

This is an exciting day for GeekCap: the day that we moved from Cloud 1.0 to Cloud 3.0. Let me explain what I mean.
The move to the cloud came in three waves:
- 1.0: Running virtual machines in the cloud
- 2.0: Running containers across a set of virtual machines in the cloud
- 3.0: Running serverless functions against serverless services
History

The waves started with Amazon Web Services as they made their excess inventory of virtual machines available to other companies by exposing Elastic Cloud Compute (EC2). No longer did companies need to request a virtual machine from an internal operations organization and wait days or months for that virtual machine to become available. EC2 enabled them to provision virtual machines on-demand in a matter of minutes. This was the beginning of the "pets vs cattle" concept in how virtual machines were treated. Virtual machines used to be "pets": we would care for them, ssh into them, install security patches, closely monitor their uptime, restart them, and so forth. But in the paradigm of "cattle", virtual machines became disposable: we create them, run them, and when we have a new version of the software ready to run on them, we would kill them and start new ones. Rarely would we ssh into them or install updates, we would simply discard the old one and create a new one.
Then we saw the wave of containerization. Containers provide more flexibility:
- Developers can run a container locally knowing that the same container will run in production
- With a container engine running on a virtual machine, a container can run in any programming language; you can use the technology that best solves a business problem inside your container
- Containers start much faster than virtual machines, giving us true elasticity
We provision a cluster of virtual machines using technologies like Kubernetes or Amazon ECS, and deploy as many containers to those virtual machines as we need to run our business. Containers are fast to build and quick to deploy, so we almost never ssh into them, we never patch them, and most are very short-lived.
Finally, we saw the wave of serverless. With the advent of AWS Lambda, Azure Functions, and Google Functions, we no longer need to rely on provisioning our own infrastructure, we are now free to use someone else's infrastructure that they provision on-demand for us as our functions are invoked. Furthermore, our deployment units are no longer virtual machines or containers, but light-weight functions that encompass our business logic. This allows us to focus on our business logic instead of the plumbing to make it work.
It is important to note that serverless is really a misnomer because our application do run on servers, just not servers that we're responsible for. From invocation-to-invocation, there is no guarantee that we'll receive the same function running on the same server, all of those decisions are made by the cloud service provider.
Serverless Applications
The goal in designing a serverless architecture is to run a full-stack application without managing any servers ourselves, so running serverless functions is only one part of the solution. We also need to account for:
- Data
- Static Resources
- User management and authentication
- Asynchronous Communications
- Web Hosting
GeekCap does not yet use all of these, but let me review the technologies that we employed to build a dynamic content website.
Data
One of the challenges in developing an application as a collection of serverless functions is that, in order to be useful, those functions need to access data. Fortunately, there are several good options for managing data using a service that does not require that we provide the infrastructure. In AWS, DynamoDB is a NoSQL database that can host terabytes of data and its billing model is based on the amount of stored data and the number of read/write access operations. In fact, with the free tier limits, if we have little data and little load, we pay nothing. If we have a lot of data and a lot of load then presumably we also have revenue that pays for our cloud costs.
Amazon RDS is a good option for SQL database management, but it does not fit well into the serverless model. Yes, Amazon manages the servers upon which the database runs, but it requires that you provide an EC2 instance for it to run on. This means that you incur a monthly cost even when you do not have any load. So why technically it does not require you to manage your own server, it does not fit well into a serverless model.
When building GeekCap we opted to use DynamoDB to manage our dynamic content, which includes all of the meta data about the articles you are reading, such as the article's title, subtitle, abstract, and so forth.
Static Resources
Websites and mobile applications always have need of accessing static resources, and Amazon S3 is the perfect solution for managing static resources. Amazon S3 is an object store that organizes its data into buckets and provides controlled access to those objects. Objects can be publicly accessible or can be managed using Amazon's Identity and Access Management (IAM) roles and groups. And do not let the term "object" discourage you, HTML files and images can be stored as objects in S3.
When building GeekCap we opted to store article content and images in S3. This article, for example, is located in an S3 bucket in the path /content/geekcap-serverless/index.html.
Web Hosting
There are plenty of good services that will allow you to host a static website, and some that will integrate with a content management system, such as WordPress. But a feature of Amazon S3 is that a bucket can be configured to serve a static website. You can provide an index.html page in the root of your S3 bucket and, when you open your browser to the bucket, S3 will automatically serve the file back to your browser. Furthermore, you can configure your domain's DNS server to send requests to your bucket so that when you access a website, like www.geekcap.com, you are actually viewing the web page from the S3 bucket.
When building GeekCap we opted to use Amazon S3 with a bucket configured as a static website.
Single-Page Applications (SPAs)
Serving static content is nice and all, but it does not make for a very engaging user experience. The solution is to leverage a single-page application (SPA) technology like Angular or React to create an engaging user experience.
When building GeekCap we opted to build the application using React and deploy the production build to our S3 bucket. I will share how to do this in a subsequent article, but it is a very simple process. We built the application using create-react-app, which includes a build script that can be invoked as follows:
npm run buildThis creates a build directory that contains your production application. Copy that to your S3 bucket and you are done!
All of this is to say that when a user opens a browser window to your website, your DNS server redirects the request to your S3 bucket, which serves up your index.html page. This page is a React application that retrieves all required JavaScript and CSS files and presents it back to the user. For dynamic content, in invokes a lambda function through Amazon's API Gateway, which exposes your function as a RESTful endpoint, which in turn retrieves data from DynamoDB. Static content is loaded directly from the S3 bucket using familiar URL paths.
GeekCap High Level Architecture
GeekCap was initially deployed in 2009 to AWS in a Cloud 1.0 deployment. We had a simple Web user interface that was built in Spring MVC with JavaServer Pages, a set of RESTful services, also built in Sping MVC, both running in an EC2 instance, and a separate virtual machine running MongoDB, connected to an EBS volume to persist our data. The performance was good and Amazon's availability was incredible (we had at most an outage every year or two), but we still had a cloud bill to host our EC2 instances and attached storage. Because I have been doing so much work in AWS and writing about AWS Lambdas, I felt that it was time that we attempted to rebuild the website using a serverless architecture.
Figure 1 shows the initial high-level architecture for the GeekCap website.
Figure 1. GeekCap High-Level Architecture
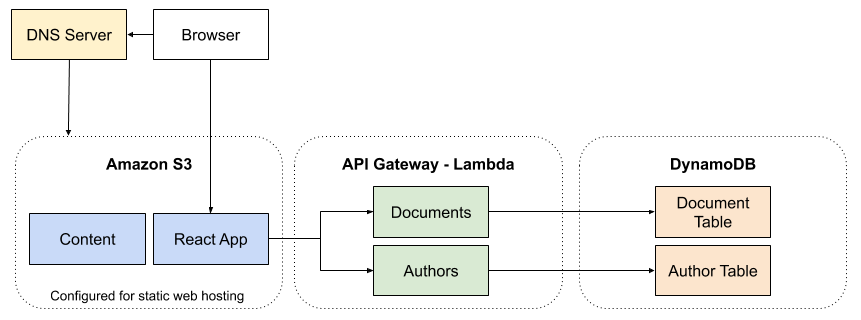
To build the GeekCap website using a fully serverless architecture, we did the following:
- Created an S3 bucket and configured it to serve up a static web site
- Configured our DNS server to direct requests to our
wwwCNAMEto our S3 bucket - Implemented our services as Lambdas, using the Serverless Framework, which deploys Lambdas, sets up API Gateway to expose those Lambdas as RESTful endpoints, and creates our DynamoDB tables and indexes
- Built our user interface using React
- Configured our React actions to query our Lambdas through API Gateway
- Uploaded our React application and static content to S3
Conclusion
There is still a lot of work to be done, but this initial exercise proved that we could move away from virtual machines and containers and run a rich web application completely serverlessly! AWS Lambda, S3, and DynamoDB can scale beyond what we can expect to face and our bill is based on the amount of data we have and how frequently it is accessed. Look for more about how well this architecture works for us in the coming months.